
写一个大型游戏外挂难吗?(例如CF LOL)?
其实也不算难,FPS游戏发展至今,阻挡外挂开发者脚步的往往不是数据和功能开发,而是高难度的检测。
现如今,检测的手段越来越多,也越来越五花八门。列如:
检测参数,检测堆栈,检测注入等等。
CRC是众多检测手段中最为常见的,同时在各大新手和老鸟之间也广为津津乐道。那么今天和大家一起慢慢揭开“神秘”的CRC。
先来了解一下什么是CRC,百科给我们的解释是:
CRC即循环冗余校验码(Cyclic Redundancy Check):是数据通信领域中最常用的一种查错校验码,其特征是信息字段和校验字段的长度可以任意选定。循环冗余检查(CRC)是一种数据传输检错功能,对数据进行多项式计算,并将得到的结果附在帧的后面,接收设备也执行类似的算法,以保证数据传输的正确性和完整性。
在游戏领域,咱们通俗易懂的讲,CRC即是对比。既然是对比,那么就需要两个值,一个是被修改的地址/代码段的值,一个是用作对比的值。当地址的值 !=对比的值,那么反作弊系统将通过发包等手段告诉服务器,进行踢下线,封号等操作。
那么,CRC一般在内存中都长什么样的呢?举个例子:
某内存代码段中,出现以下代码:
mov eax,xxx
CMP eax,1
jnz xxxxxxxx
假设,jnz这局代码是执行换弹完毕的动作,那么咱们想要零秒换弹的功能,在服务器不做验证的情况下,咱们可以修改cmp 或者 jnz为 JMP,在换子弹的时候,强制执行换弹完毕的动作,那么如果改了这个地方,CRC会如何查?
首先 JNZ xxxxxxxx 二进制的代码 模样如下
即 0F 85 xxxxxxxx
那么,咱们再来看看,JMP的模样
即 E9 xxxxxxxx
假如,我将此处改成CALL?他又会变成什么样?
E8 xxxxxxxx
通过对比,相信大家知道哪里发生了变化。
原代码, 为 0F 85 但是不管你如何修改,此处都会发生变化,CRC扫描的即是这个变化的值。
在某个地方,可能有这样一串效验的代码:
mov eax,刚刚JNZ代码段的值
cmp eax,0f85
jnz 是否上报异常
在此检测代码处,咱们是不是又可以给他修改,不让其执行上报的代码?
同样,其他地方,也可以查询此处是否被修改。那么咱们要伪造几层,处理多少个地方,取决于游戏查了几层,验证了多少地方。
通过以上的例子,相信大家对CRC有了简单的了解。
接下来咱们实际的去游戏中,更深层的揭露它的“面纱”。
相信穿越火线(cf)大部分人都知道,一个发展了十多年的老游戏,检测技术已经相当成熟,有很多地方值得我们学习和借鉴。
以该游戏的内存透视为例子(基址由网络收集) 7B65CC
该地址在未修改的情况下,默认的值为16777217 即十六进制的1000001,那么,将1000001改为某些值的时候,即可实现透视效果,在这里可以简单的猜测和了解一下该透视的实现原理,当然这不是本文主要探讨的内容。——该地址可能与游戏中的某些模型有关,D3D渲染引擎读取该地址的值,当人为的修改后,即改变了渲染的顺序或者加载不了某些模型实现透视效果。
效果图如下:
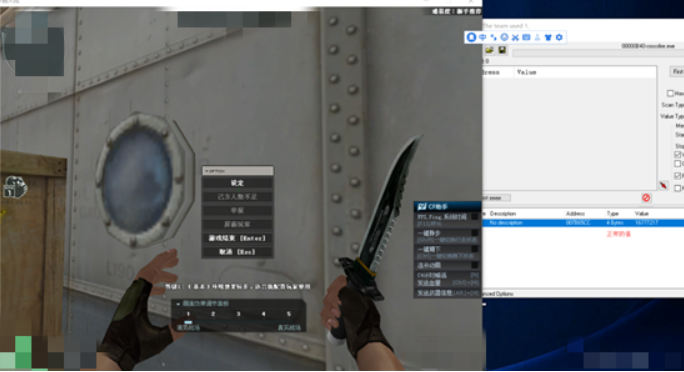
此时此刻,人物透视实现了,同时也改变了该地址的值,如此关键的位置,肯定是有CRC或者其他手段在循环检测,即循环访问该地址,咱们右键查看访问该地址的代码,如下图:
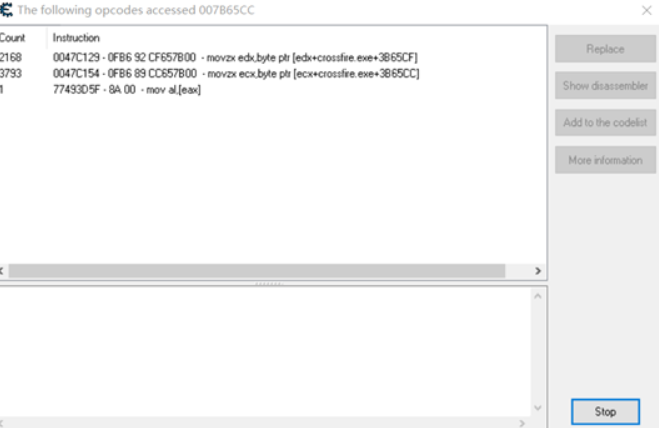
经过观察发现, 前两条代码基本可以忽略,因为检测代码不可能在短短几秒钟内访问上千次。值得关注的是第三条访问代码,每隔3秒钟进行一次访问,是不是和印象中的检测很像呢?
该代码究竟起了什么作用,是不是让多数人束手无策的"CRC"?,咱们一步步把它“扒光”便知。
OD附加后,跳转至该访问代码处:
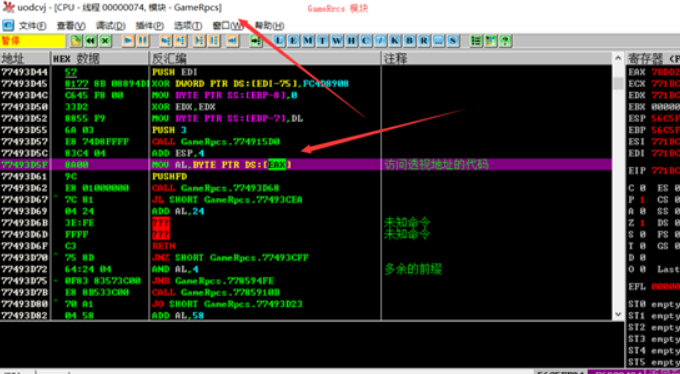
发现如上,代码段位于 gamerpcs模块,那么这个时候咱们就要先记一下该地址位于模块中的所处位置,防止游戏奔溃导致数据丢失 计算出该地址为 GameRpcs.dll+33D5F。
记录好后,在该位置下段,咱们观察一下EAX的值

EAX=007B65CF[007B65CF]=0x101
跟咱们内存透视地址007B65CC是不是很接近呢?
那么把该地址拿到CE中进行观察和对比,如下图
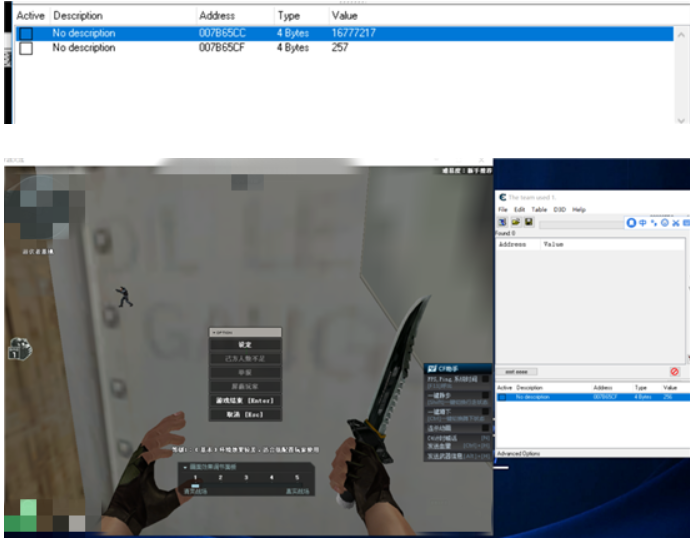
当我们修改[eax],发现依旧可以实现透视,那么可以确定,实际可以实现透视的是007B65CF,也就是基地址 +3的位置,同时,他检测应该也是针对007B65CF。
回过头来观察代码:
09C83D5F 8A00 MOV AL,BYTE PTR DS:[EAX]
09C83D61 9C PUSHFD
09C83D62 E8 01000000 CALL GameRpcs.09C83D68
[EAX]传值给 AL
然后进行一个CALL
[EAX]里面存放的是什么?
正常不修改的情况,存放的是0x101
如果修改了就会变成修改的值。
假设下面的CALL是检测对比(八九不离十),只要咱们给AL所传递的值是正确的,不管下面的CALL如何检测,所得出的返回值都是正确的。
再次下段验证,传递给AL的是不是被修改过的值呢? 如下图:
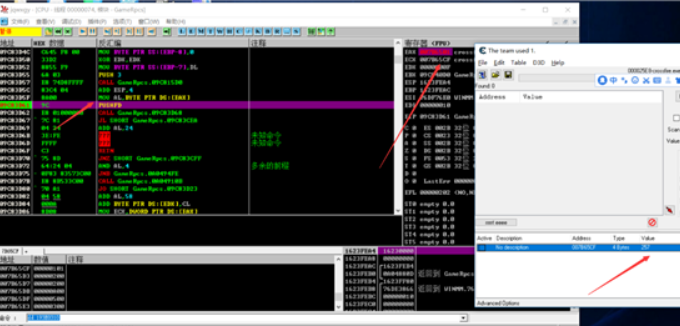
原来的值,未修改
给AL传递的是0x01
那么修改该地址的值,再次下段验证
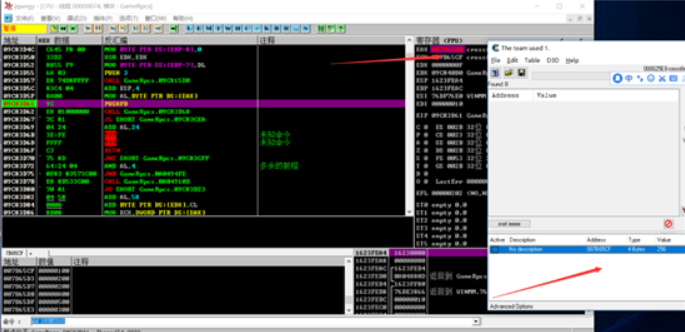
修改过后,给AL传递的值是0x00
从上面两图所得出,他实际传入/检测的值是007B65CF的最后一个字节,再次将值修改为其他下段验证:
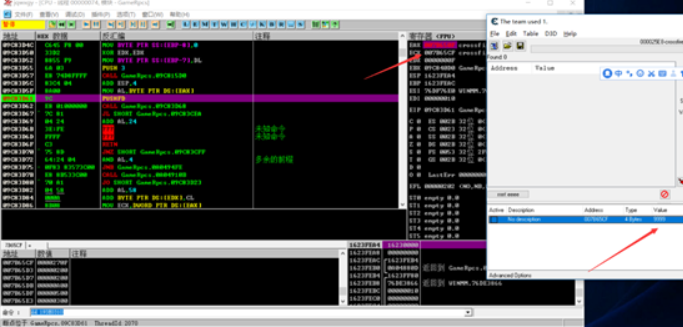
通过多次下段验证,确认了传递给AL的值就是“透视地址”的值,如果给他传递的值不正确,服务器就会知道你修改内存,进行封号,踢下线等等操作。
知道了此处代码的作用,应该如何进行伪造?
直接NOP?不让其执行检测代码?
那肯定是不行的。
将检测CALL或者某些关键的位置NOP,不让其执行检测代码,这是早期最为常用的手段。而经过这么多年的发展,游戏公司和逆向工作者都在进步。
假设将该CALL 在某处 NOP不让其执行,确实不会触发检测代码。但是假如CALL内有必要的心跳要发送至服务器,同时也会将心跳截断,服务器也会知道你修改了内存代码。
最好的办法就是在不影响代码正常执行的情况下进行伪造,可以在适当的位置进行HOOK,在自己的函数中给AL/或者eax赋值,即0x01或0x101。
hook代码如下图(OD版):
56AF3D5C 83C4 04 add esp, 4 在此处下HOOK
56AF3D5F 8A00 mov al, byte ptr[eax]还原这两条代码
56AF3D61 9C pushfd 跳回这个地址

如此一来,在不影响代码正常执行的情况下便成功伪造了地址正常的值。
假设他有多重检测,下一个检测地方应该在哪里?

咱们修改了内存代码段,使其发生了变化,如果多重扫描和检测,只需扫描此处修改的JMP,当然,咱们也可以在此处下段,继续伪造。他检测了多少层,那就就伪造多少层
以下是C++版本伪造例子
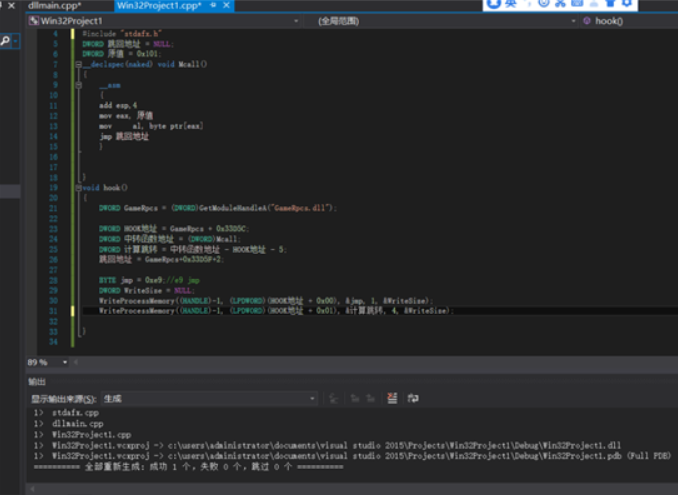
技术就简单分享到这里,感兴趣的可以找我交流学习,15年技术沉淀
参考下图

public void calc(){
articleWordMap=new HashMap<String, Integer>();
//读取文章
calcFreauency(articleWordMap,new File("/home/geekgao/朴素贝叶斯/500trainblogxml/positiveout/1377331000713.txt"));
keepEmotionWord(articleWordMap);
double allBackPos=1;
double allBackNeg=1;
double allBackUns=1;
Set<String> word=articleWordMap.keySet();
for (Iterator it=word.iterator();it.hasNext();){
String tmp=(String)it.next();
double back;
if (backPositive.containsKey(tmp)){
back=backPositive.get(tmp);
allBackPos=Math.pow(back,articleWordMap.get(tmp)) * allBackPos;
}
if (backNegative.containsKey(tmp)){
back=backNegative.get(tmp);
allBackNeg=Math.pow(back,articleWordMap.get(tmp)) * allBackNeg;
}
if (backUnsure.containsKey(tmp)){
back=backUnsure.get(tmp);
allBackUns=Math.pow(back,articleWordMap.get(tmp)) * allBackUns;
}
}
double resultPositive;
double resultNegative;
double resultUnsure;
resultPositive=priorPositive * allBackPos;
resultNegative=priorNegative * allBackNeg;
resultUnsure=priorUnsure * allBackUns;
System.out.println("积极:" + resultPositive);
System.out.println("消极:" + resultNegative);
System.out.println("不确定:" + resultUnsure);
}
//解析出文章中的词语,并且映射上频数
public void calcFreauency(Map<String,Integer> wordMap,File article){
try{
//取得dom4j的解析器
SAXReader reader=new SAXReader();
//取得代表文档的Document对象
Document document=reader.read(article);
//取得根结点
Element root=document.getRootElement();//取得根节点<document>
List<?> list1=root.elements();//取得<document>的子节点
List<?> sentence_list=((Element)list1.get(0)).elements();//<content>下的<sentence>集合
List<?> tok_list;//<sentence>下的<tok>集合
//遍历<sentence>节点
for (int i=0; i < sentence_list.size(); i++){
tok_list=((Element)sentence_list.get(i)).elements();//获得每个sentence的tok集合
for (int j=0;j < tok_list.size();j++){
setWordMap((Element)tok_list.get(j),wordMap);
}
}
}catch (DocumentException e){
e.printStackTrace();
}
}
public void setWordMap(Element tok,Map<String,Integer> wordMap){
String type,text;
List<?> list;
if (!(tok.getName().equals("tok"))){//如果不是tok节点,那么就不用处理了
return ;
}